
티스토리 뷰
728x90
Deep learning basic
Convolutional neural networks
- 간단하게 cnn을 통해 어떻게 특징들을 파악하는지 아래 gif를 통해 느껴보자.
- 아래는 mnist라는 손글씨 데이터셋을 cnn을 통해 학습할 때 각 layer에서 어떤 특징들이 추출되는지 보여주는 예시
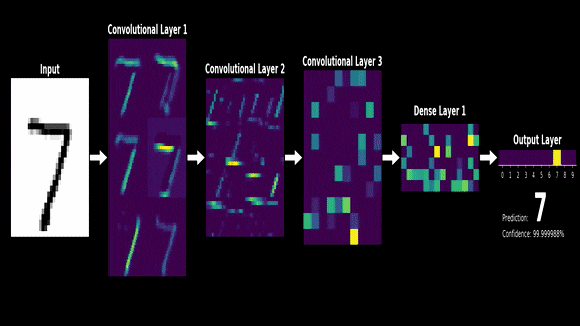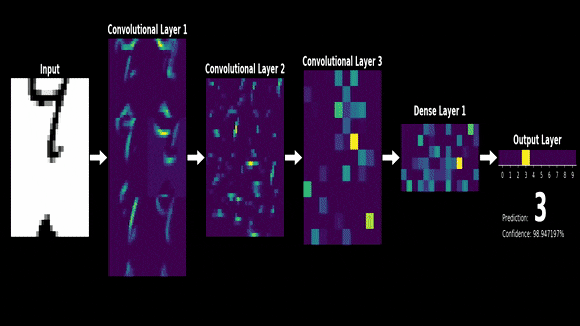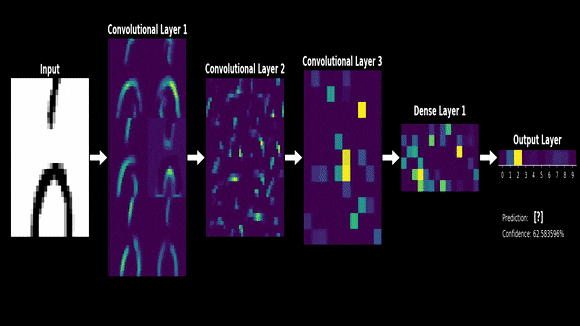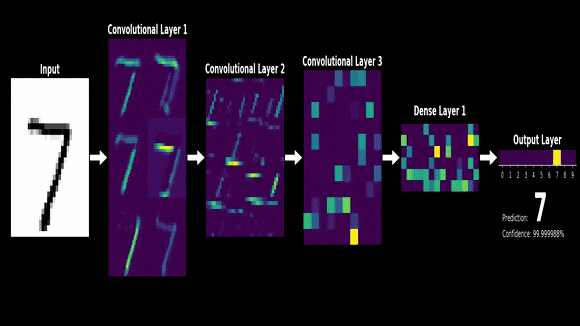

- 시그널 프로세싱에서 두 함수가 있을 때 두개의 함수를 잘 섞어주는 방법으로서 제시되었음
- 2d image convolution의 수식을 보면 I는 전체 이미지공간에서 K라는 필터를 적용해서 정보를 추출해내는 것을 의미

- Convolution filter란 무엇일까?
- 사진을보면 K라는 필터는 $3\times3$ filter이고 오른쪽 I는 $7\times7$ 이미지를 나타낸다. 이 때 K필터는 stride=1(skip한 간격)을 기본으로 맨 왼쪽 상단부터 시작하여 모든 이미지 공간을 지나간다.
- 이때 output이 나오는데 각 필터값과 이미지값의 곱의 합으로 계산된 값이 된다.
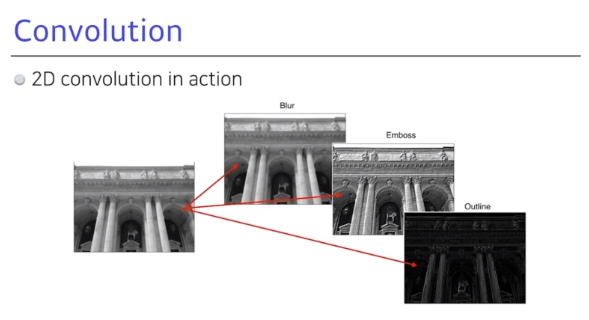
- 어떤 필터를 사용하는지에 따라 blur가 되거나 emboss가 되거나 outline만 강조한 이미지가 나올 수 있다. 예컨대 3x3 필터의 각 값이 1/9로 되어 있다면, 이는 모든 값이 필터의 평균값의 합이 되므로 blur된 output이 나오게 된다.
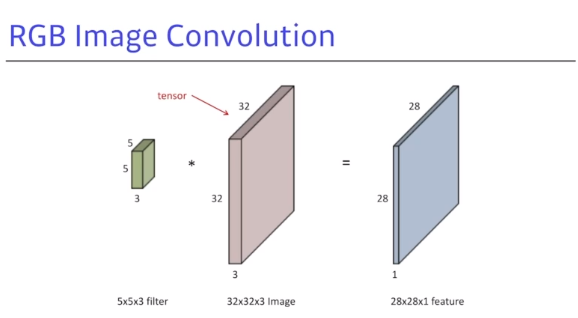
- 일반적으로 이미지는 rgb값을 가지고 있기 때문에 filter는 암묵적으로 3채널에 대한 depth를 가지고 있다.
- 사진을 보면 $5\times5\times3$ 필터가 $32\times32\times3$의 이미지를 지나가게 되면 output을 $28\times28\times1$ feature map이 나오게 된다.

- 만약에 필터가 여러개라면, feature map도 필터의 수만큼 나올 것이다.

- 위에서 배운 내용을 가지고 convolution을 stack할 수 있다.
- 만약에 32x32x3짜리 image에서 $28\times28\times4$의 feature map을 만들기 위해 필요한 parameter 수는 input chan * output chan * filter size가 되기에 1번째 $32\times32\times3$에서 $28\times28\times4$가 되기 위한 필요 파라미터 수는 $5\times5\times3\times4$가 된다.
- 두번째에서는 $5\times5\times4\times10$이 될 것이다.

- Convolution network 는 Conv 하는 과정과 pooling, fc로 나눠질 수 있다.
- pooling은 앞서 컨볼루션 과정에서 뽑았던 정보들을 이들의 합이나 평균으로(maxpool, avgpool, ...) 만들어주고 이를 fc를 통해 원하는 task에 적용할 수 있다(classification, regression ...)
- 요즘은 fc layer를 줄이거나 다른 layer로 대체한다. 이는 파라미터수가 fc layer로 넘어갈 때 매우 크게 늘어나기 때문이다.
- 파라미터수가 높을수록 일반화가 어렵기 때문에 layer가 깊어져도 각 레이어가 가지는 파라미터수는 적어지는 것이 좋다.
- ※ 어떤 모델이 파라미터수를 어떤식으로 가져가는 지 알아보는 감이 중요함
Conv에서 알아야하는 기본 하이퍼파라미터
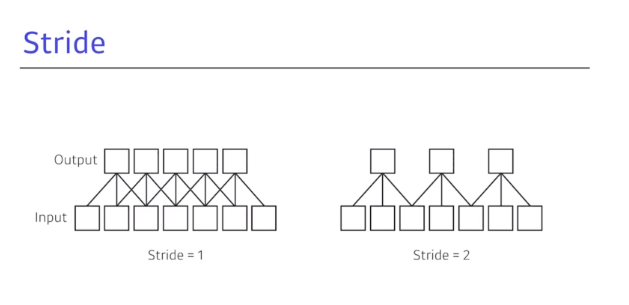
- stride는 얼마나 필터를 dense하게 또는 sparse하게 찍을 것인가?에 대한 파라미터이고 default는 1이다.
- 2d conv에서는 stride가 width, height방향으로 진행된다.

- conv filter를 적용하면 항상 차원이 줄기 마련이다. 또한 conv filter는 가장자리 정보를 가져갈 수 없다.
- 이를 해결하고자 padding이라는 파라미터를 활용하여 내가 원하는 dims 차원을 output으로 내보낼 수 있고 동시에 edge정보를 확보할 수 있다.
Conv 파라미터 수 계산하기
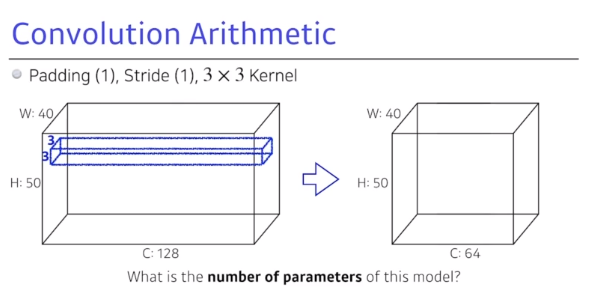
- 위의 그림에서 필요한 파라미터 수는 $3\times3\times128\times64 = 73,728$ 이 된다.
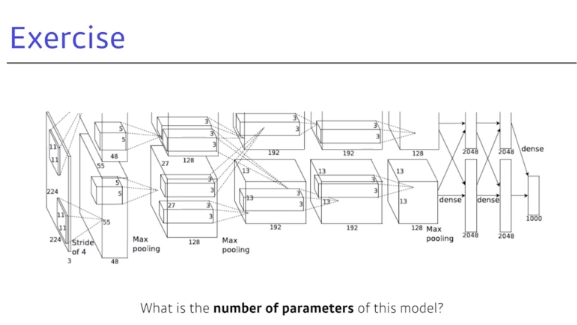
- 위의 그림에서 필요한 파라미터 수는
- $11 \times 11 \times 3 \times 48 \times 2 = 35,000$
- $5 \times 5 \times 48 \times 128 \times 2 = 307,000$
- $3 \times 3 \times 128 \times 192 \times 2 = 884,000$
- $3 \times 3 \times 192 \times 192 \times 2 = 663,000$
- $3 \times 3 \times 192 \times 128 \times 2 = 442,000$
- $13 \times 13 \times 128 \times 2 \times 2048 \times 2 = 177,000,000$
- $2048 \times 2 \times 2048 \times 2 = 16,000,000$
- $2048 \times 2 \times 1000 = 4,000,000$

- $1\times1$ conv를 활용하면 차원을 원하는 차원으로 바꿀 수 있으며 parameter 수를 줄일 수 있기 때문에 더 깊게 layer를 올릴 수 있는 도구가 된다.
Simple CNN Code with Pytorch ( Implementation )
- 보통은 conv - batchnorm - act - dropout - pool 순서로 이루어짐 (cs231n)
- nn.Sequential을 활용하여 깔끔하게 만들 수 있음
- basic_conv_block을 만들어서 반복하는 conv 과정을 다른 def로 만들 수 있음
import torch
import torch.nn as nn
class SimpleCNN(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, stride=1, padding=1) # 커널사이즈 3*3, stride 1, padding 1
self.batchnorm1 = nn.BatchNorm2d(16)
self.conv2 = nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, stride=1, padding=1)
self.batchnorm2 = nn.BatchNorm2d(32)
self.conv3 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=1, padding=1)
self.batchnorm3 = nn.BatchNorm2d(64)
self.fc = nn.Linear( 64*28*28, 10)
self.pool = nn.MaxPool2d(2)
self.activation = nn.ReLU()
def forward(self, x):
B = x.shape[0]
display(x.shape) # torch.Size([2, 3, 224, 224]) [batch, channel, height, width]
x = self.conv1(x)
x = self.batchnorm1(x)
x = self.activation(x)
x = self.pool(x)
display(x.shape) # torch.Size([2, 16, 112, 112])
x = self.conv2(x)
x = self.batchnorm2(x)
x = self.activation(x)
x = self.pool(x)
display(x.shape) # torch.Size([2, 32, 56, 56])
x = self.conv3(x)
x = self.batchnorm3(x)
x = self.activation(x)
x = self.pool(x)
display(x.shape) # torch.Size([2, 64, 28, 28])
x = x.reshape(B, -1)
display(x.shape) # torch.Size([2, 50176]) - 64 * 28 * 28
x = self.fc(x)
display(x.shape) # torch.Size([2, 10])
return x
batch_image = torch.rand(2, 3, 224,224, dtype=torch.float32) # [batch, channel, height, width]
model = SimpleCNN()
result = model(batch_image)정리
- Conv라는 과정은 I라는 이미지공간에서 conv filter를 적용시켜 이미지 패턴과 특징을 추출하는 것
- 어떤 필터를 적용하는가에 따라서 다른 특징들이 추출
- conv 모델의 파라미터를 추정할 수 있어야 함
- filter size * filter size * in channels * out channels
- conv 모델을 만들 때 필요한 파라미터
- filter size
- stride
- padding
- cnn모델에서 기본적으로 parameter의 수를 줄이면서 깊이를 깊게 가져가는 것이 학습과 성능에 좋음
- $1 \times 1$ filter는 같은 특징들의 depth 크기(channel방향) 줄일 수 있어서 활용
- 참고
- 네이버 부스트코스 : 딥러닝 기초 강의
- cs231n 강의

댓글